Note: this posting is based on an incorrect number from an Amazon slide. I’ve now re-done the revenue numbers.
 We’ve been playing around with Amazon’s Simple Storage Service (S3).
We’ve been playing around with Amazon’s Simple Storage Service (S3).
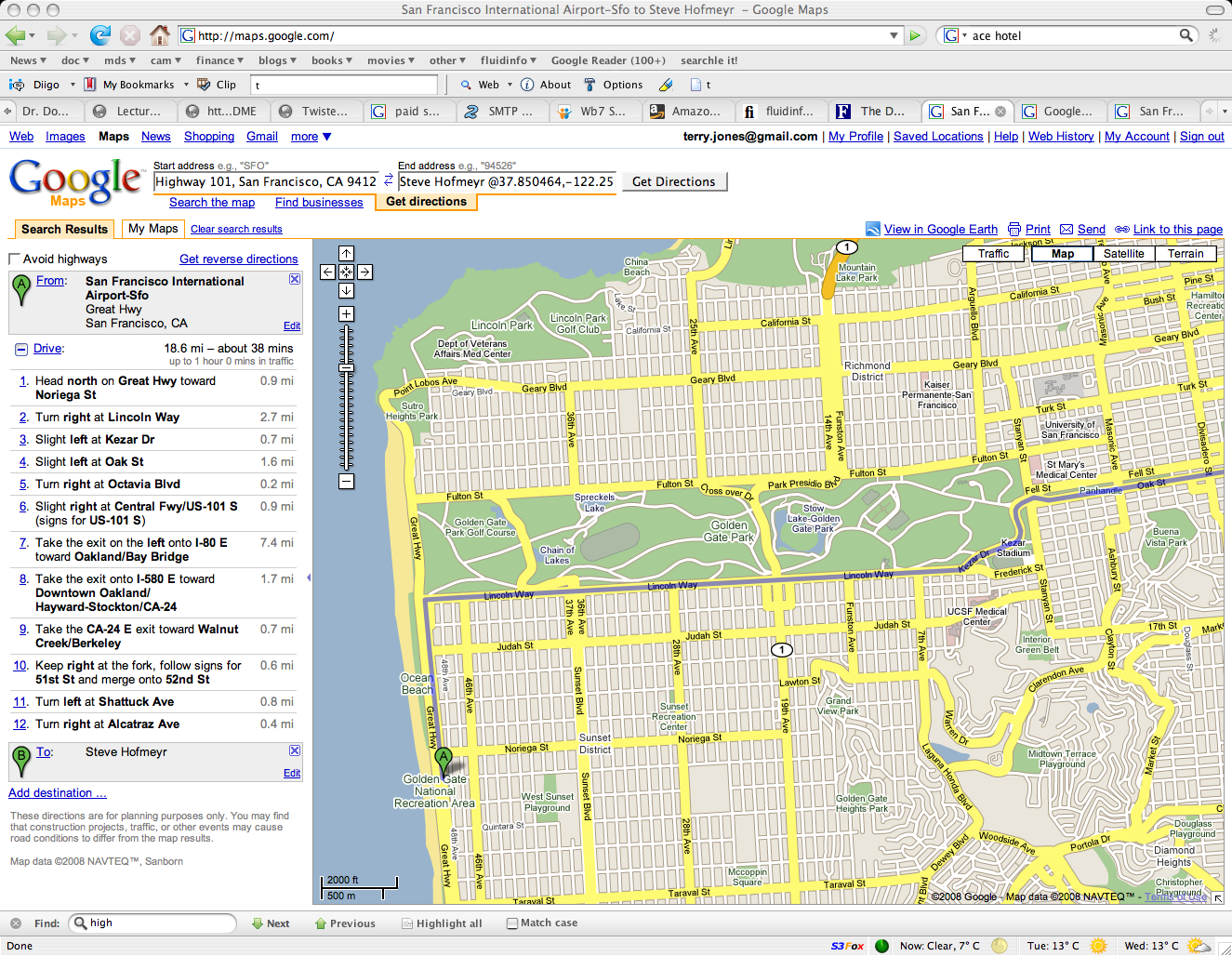
Adam Selipsky, Amazon VP of Web Services, has put some S3 usage numbers online (see slides 7 and 8). Here are some numbers on those numbers.
There were 5,000,000,000 (5e9) objects inside S3 in April 2007 and 10,000,000,000,000 (1e13) in October 2007. That means that in October 2007, S3 contained 2,000 times more objects than it did in April 2007. That’s a 26 week period, or 182 days. 2,000 is roughly 211. That means that S3 is doubling its number of objects roughly once every 182/11 = 16.5 days. (That’s supposing that the growth is merely exponential – i.e., that the logarithm of the number of objects is increasing linearly. It could actually be super-exponential, but let’s just pretend it’s only exponential.)
First of all, that’s simply amazing.
It’s now 119 days since the beginning of October 2007, so we might imagine that S3 now has 2119/16.5 or about 150 times as many objects in it. That’s 1,500,000,000,000,000 (1.5e15) objects. BTW, I assume by object they mean a key/value pair in a bucket (these are put into and retrieved from S3 using HTTP PUT and GET requests).
Amazon’s S3 pricing for storage is $0.15 per GB per month. Assume all this data is stored on their cheaper US servers and that objects take on average 1K bytes. These seem reasonable assumptions. (A year ago at ETech, SmugMug CEO Don MacAskill said they had 200TB of image data in S3, and images obviously occupy far more than 1K each. So do backups.) So that’s roughly 1.5e15 * 1K / 1G = 1.5e9 gigabytes in storage, for which Amazon charges $0.15 per month, or $225M.
That’s $225M in revenue per month just for storage. And growing rapidly – S3 is doubling its number of objects every 2 weeks, so the increase in storage might be similar.
Next, let’s do incoming data transfer cost, at $0.10 per GB. That’s simply 2/3rds of the data storage charge, so we add another 2/3 * $225M, or $150M.
What about the PUT requests, that transmit the new objects?
If you’re doubling every 2 weeks, then in the last month you’ve doubled twice. So that means that a month ago S3 would have had 1.5e15 / 4 = 3.75e14 objects. That means 1.125e15 new objects were added in the last month! Each of those takes an HTTP PUT request. PUTs are charged at one penny per thousand, so that’s 1.125e15 / 1000 * $0.01.
Correct me if I’m wrong, but that looks like $11,250,000,000.
To paraphrase a scene I loved in Blazing Saddles (I was only 11, so give me a break), that’s a shitload of pennies.
Lastly, some of that stored data is being retrieved. Some will just be backups, and never touched, and some will simply not be looked at in a given month. Let’s assume that just 1% of all (i.e., not just the new) objects and data are retrieved in any given month.
That’s 1.5e15 * 1K * 1% / 1e9 = 15M GB of outgoing data, or 15K TB. Let’s assume this all goes out at the lowest rate, $0.13 per GB, giving another $2M in revenue.
And if 1% of objects are being pulled back, that’s 1.5e15 * 1% = 1.5e13 GET operations, which are charged at $0.01 per 10K. So that’s 1.5e13 / 10K * $0.01 = $15M for the GETs.
This gives a total of $225M + $150M + $11,250M + $2M + $15M = $11,642M in the last month. That’s $11.6 billion. Not a bad month.
Can this simple analysis possibly be right?
It’s pretty clear that Amazon are not making $11B per month from S3. So what gives?
One hint that they’re not making that much money comes from slide 8 of the Selipsky presentation. That tells us that in October 2007, S3 was making 27,601 transactions per second. That’s about 7e10 per month. If Amazon was already doubling every two weeks by that stage, then 3/4s of their 1e13 S3 objects would have been new that month. That’s 7.5e12, which is 100 times more transactions just for the incoming PUTs (no outgoing) than are represented by the 27,601 number. (It’s not clear what they mean by transaction – I mean what goes on in a single transaction.)
So something definitely doesn’t add up there. It may be more accurate to divide the revenue due to PUTs by 100, bringing it down to a measly $110M.
An unmentioned assumption above is that Amazon is actually charging everyone, including themselves, for the use of S3. They might have special deals with other companies, or they might be using S3 themselves to store tons of tiny objects. I.e., we don’t know that the reported number is of paid objects.
There’s something of a give away the razors and charge for the blades feel to this. When you first see Amazon’s pricing, it looks extremely cheap. You can buy external disk space for, e.g., $100 for 500GB, or $0.20 per GB. Amazon charges you just $0.18 per GB for replicated storage. But that’s per month. A disk might last you two years, so we could conclude that Amazon is e.g., 8 or 12 times more expensive, depending on the degree of replication. But you don’t need a data center or to grow (or shrink) a data center, cooling, employees, replacement disks—all of which have been noted many times—so the cost perhaps isn’t that high.
But…. look at those PUT requests! If an object is 1K (as above), it takes 500M of them to fill a 500GB disk. Amazon charges you $0.01 per 1000, so that’s 500K * $0.01 or $5000. That’s $10 per GB just to access your disk (i.e., before you even think about transfer costs and latency), which is about 50 times the cost of disk space above.
In paying by the PUT and GET, S3 users are in effect paying Amazon for the compute resources needed to store and retrieve their objects. If we estimate it taking 10ms for Amazon to process a PUT, then 1000 takes 10 seconds of compute time, for which Amazon charges $0.01. That’s nearly $26K per month being paid for machines to do PUT storage, which is 370 times more expensive than what Amazon would charge you to run a small EC2 instance for a month. Such a machine probably costs Amazon around $1500 to bring into service. So there’s no doubt they’re raking it in on the PUT charges. That makes the 5% margins of their retailing operation look quaint. Wall Street might soon be urging Bezos to get out of the retailing business.
Given that PUTs are so expensive, you can expect to see people encoding lots of data into single S3 objects, transmitting them all at once (one PUT), and decoding when they get the object back. That pushes programmers towards using more complex formats for their data. That’s a bad side-effect. A storage system shouldn’t encourage that sort of thing in programmers.
Nothing can double every two weeks for very long, so that kind of growth simply cannot continue. It may have leveled out in October 2007, which would make my numbers off by roughly 2119/16.5 or about 150, as above.
When we were kids they told us that the universe has about 280 particles in it. 1.5e15 is already about 250, so only 30 more doubling are needed, which would take Amazon just over a year. At that point, even if all their storage were in 1TB drives and objects were somehow stored in just 1 byte each, they’d still need about 240 disk drives. The earth has a surface area of 510,065,600 km2 so that would mean over 2000 Amazon disk drives in each square kilometer on earth. That’s clearly not going to happen.
It’s also worth bearing in mind that Amazon claims data stored into S3 is replicated. Even if the replication factor is only 2, that’s another doubling of the storage requirement.
At what point does this growth stop?
Amazon has its Q4 2007 earnings call this Wednesday. That should be revealing. If I had any money I’d consider buying stock ASAP.

 I’ve been playing with Keynote to make a presentation. There are a lot of things I don’t really like about using a Mac, but Keynote is not one of them.
I’ve been playing with Keynote to make a presentation. There are a lot of things I don’t really like about using a Mac, but Keynote is not one of them.
 On the left is an addition problem. If you know the answer without thinking, you’re probably a geek.
On the left is an addition problem. If you know the answer without thinking, you’re probably a geek. Let’s instead think about the problem in binary (i.e., base 2). In binary, the sum looks like the image on the right.
Let’s instead think about the problem in binary (i.e., base 2). In binary, the sum looks like the image on the right.